近日 AMD 邀请了部分媒体和分析师参与了 Zen 架构新处理器的进一步细节的讨论。这篇文章里我们将讨论架构问题,并与前代处理器作一下比较。AMD Zen 架构的分支预测,解码,队列以及执行,先看幻灯片。
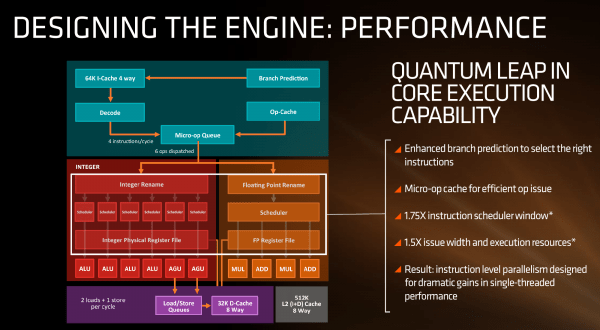
如果我们从左边开始看起,我们可以看到大部分的架构细节,包括 L1 缓存,新的微指令缓存,解码,分发,调度器,执行端口以及 load / store ( 后文以 L/S 代替 ) 单元的设计。后面的一些幻灯片描述了缓存的带宽。
首先,Zen 与前代架构的很大一处不同在于,出现了微指令缓存 ( 幻灯片上有时候写的 op 缓存,实际上意思就是 micro-op,容易误导大家 )。AMD 的推土机架构在设计上没有微指令缓存,就必须从其他缓存中提取细节,来执行频繁使用的微指令。Intel 很早就开始用微指令缓存了,效果非常好 ( 在 Core 2 处理器的 Conroe 架构上引入的重要改进 ),所以对于 AMD 来说这应该能带来不小的提升。不过 AMD 没告诉我们这个缓冲区的大小,估计在适当的时候会给出信息。
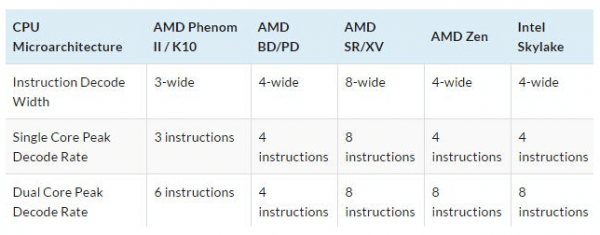
抛开含糊不清的“增强的分支预测器”不说,AMD 这次也没披露解码器的设计。但是他们表示每周期可以解码 4 条指令到队列。这个队列在微指令缓存的辅助下,到调度器时能达到最高每周期 6 条指令。因为解码器可以解码一条指令,然后该指令随后拆分为两条微指令 ( 这让指令和微指令的区别变得模糊 )。此外,这个微指令队列还能提高每个整数和浮点单元的利用率。AMD 不像 Intel 那样给整数 / 浮点一个公用的调度器,而是继续使用分离的调度器。
整数部分包括 ALU, AGU 以及 L/S 操作。L/S 单元每周期可以执行 2 次 16 字节的 load 以及 1 次 16 字节的 store 操作,利用 32KB 8 路组相连回写式 L1 数据缓存。AMD 明确说明这是回写式缓存,而不是推土机上的穿透式缓存 ( 这会在一定条件下带来大量的闲置时间 )。AMD 声称缓存内的 L/S 操作延迟会更低,但没再做进一步说明。
每核心浮点部分包括两个乘法端口,两个 ADD 端口,每周期能够执行两条捆绑的 FMAC 命令或者一条 256bit AVX。把整数和浮点部分合起来看,Zen 核心在指令级并行上将会有很大提升——提升多少取决于缓存和重排序缓存 。这次没给出 ROB 的具体数据,只说排序操作的指令调度窗口将会增大 75%,发射宽度提升 50%。即便是对天生 IPC 就低的 AMD 处理器来说,核心并行性变得越好,其他的方面也会变得有效率多了,这也使得这次用的 SMT 在多线程上占得了先机。
解密新的缓存结构
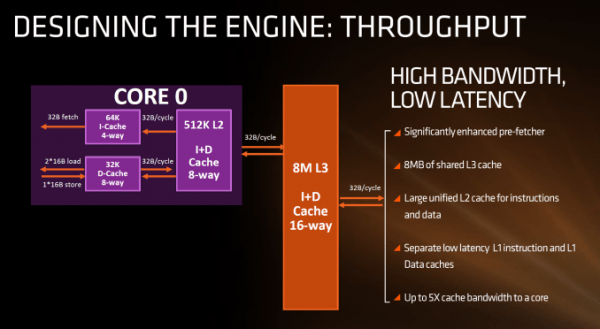
这次的缓存结构相比以前做出了重大改进,而且是朝着好的方向。相较于推土机,Zen 的 L1 缓存在大小和关联性都翻倍了,而且是写回式而不是穿透式。同时采用了非对称 L/S 单元,因为在大多数情况下 load 操作比 store 要频繁得多。指令缓存不再是两个核心共享,同时关联性也翻倍,这将减少缓存未命中的情况。AMD 声称 L1 数据和指令缓存延迟都很低,今后将公布更多细节。
L2 缓存变成了每核心 512KB,8 路相连,这是 Intel Skylake 上 256KB 4 路关联的两倍。另一方面,Intel 的 L3 缓存在高端 Skylake Core i7 处理器上是每核心 2MB,每 CPU 8MB;而在 Zen 上则是每核心 1MB,这两者都是 16 通道关联。
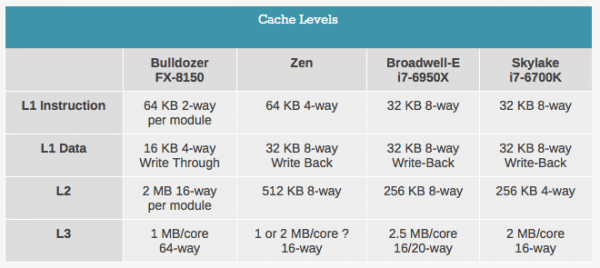
实际上,上面的幻灯在描述上是有点暧昧的。没有说多少核心共享 8MB L3,更没说是不是每颗芯片上的所有核心都是共享同一个 L3 的。然而我们从一个消息来源获得的信息 ( 在 AMD 的官方文档上找不到的那种 ) 表明,Zen 的 8 核芯片上是 4 个核心为一个簇,每个簇 4 个核心共享 8MB L3,8 核芯片有两组 8MB,共 16MB 的 L3。这样的话就是每核心 2MB,但这也说明了 Zen 的 L3 不是完全共享的,而 Intel 的则是完全共享的。这样做的原因估计和模块化有点关系,通过增加这样的模块可以做出从 4 核心直到 32 核心的各种处理器,但 Zen 的每核心 L3 和 Intel 的依然都是每核心 2MB,这没有任何优势可言。
从其他数据来看,AMD 的 L1 和 L2 比 Intel 的更大,延迟更低。而且 L1 和 L2 距离核心更近,还是每核心独立的,在单线程性能上应当会有显著提升。但更大的独立 L1 和 L2 带来的坏处是,每个核心都要监听其他核心的缓存,确保 “传递的是干净数据” 以及 “L3 上的原数据不过期”。在整体性能上,AMD 给出的总体数字是 Zen 在缓存带宽上是前代的 5 倍。
更低的功耗,FinFET 和门控时钟
在 AMD 发布 28nm APU Carrizo 和 Bristol Ridge 的时候,介绍的一个重点就是一系列降低功耗和提升能效的技术。有一部分技术延续到了 Zen 上,而且伴随着制程更新,还加入了一些新的技术。
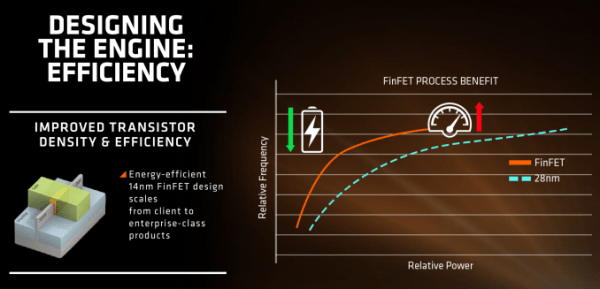
首先就是 FinFET。虽然大部分的人都已经熟悉 FinFET 到吐了,但我们还是要介绍一下。
FinFET 的设计能在给定频率下设计出晶体管的低功耗版本。每个 FinFET 代工厂给出的技术指标都不同,但 Zen 用的 GlobalFoundries / Samsung 14nm 技术和 Polaris GPU 上用的不会差太多,这意味着 AMD 使用的是 14nm 的高密度版本,能在同等功耗下达成更高性能,或者低功耗下达成同等性能。( 当然,这代工艺距离 Intel 的 14nm 工艺仍有差距 )

AMD 介绍说工程师们一直很注重功耗和能效,在性能和功能单元的效率上做了很多权衡 ( 比如提升 1% 的性能,代价是 2% 的能效损失 )。不仅有微指令缓存可以节约读取指令缓存的电能,改善的预取机制等也能减少工作量。但 AMD 也说明,为了提升能效, Zen 的门控时钟 ( Clock Gating ) 将会很激进。
AMD 第七代 APU 上其实也有差不多的设计,保持在效率最高的那个点 ( 特定性能 ) 是最好的方式。上图似乎暗示着每个核心的不同部分 (取决于用途 )都有独立的门控时钟 (比如解码单元或者浮点端口 ),虽然目前还无法确认。同时还需要有非常快速的门控时钟 ( 1-2 个周期 ),要知道门控时钟与功耗门限不同,门控时钟更难设计。
同步多线程 SMT
Zen 架构上,每个核心支持两个线程,这叫做同步多线程。Intel 版本的 SMT 早在 2008 年就开始启用了,其他的厂商比如 IBM,在 POWER 8 上支持最多 8 个线程 ( SMT8 )。让一个核心处理两个线程很困难,需要很多资源来确保线程之间不会因争夺缓存而互相阻塞。Zen 桌面版将会有 8 核 16 线程。
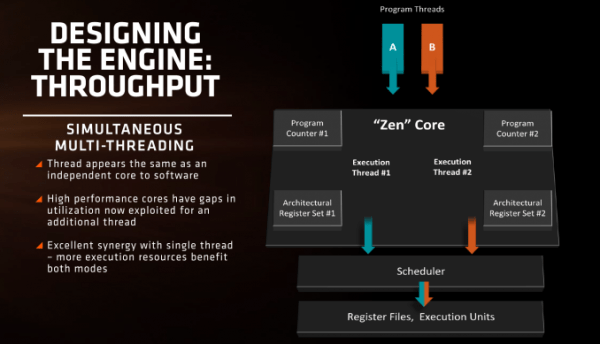
在之前的推土机上,共享浮点单元使得浮点性能不如人意。但 Zen 的设计更类似于 Intel,每个线程都和一个单独核心差不多,不会有推土机上的资源限制。有了更多的资源,SMT 将会提升 IPC,大家都很期待能知道哪些负载可言从中获益。
时间计划和供货周期
在幻灯片上写着 Zen 将会在 2017 年初大量出货 ( 这是又跳票了 )。由于 AM4 平台上 Summit Ridge 和 Bristol Ridge 使用同样的插槽,可能我们能从 AMD 的 OEM 们那里先见到 Bristol Ridge 进入市场。没有哪个主卖消费级产品的半导体厂商会在年末清仓季发布新品,而且第一季度还会有 CES 之类的大型展会。我们认为到那时候大家肯定能拿到这些新处理器。
AMD 表示随着正式发布时间的临近,会公布更多的架构细节。此外还提到了一些营销策略上的决定,比如Zen 不会是实际产品线的名称 ( 暂定的实际平台代号是 Summit Ridge,不过到了出货时候也可能会发生变化 )。
总结
这次 AMD 的介绍比媒体预想的要深入。当有人告诉我们去参加一个小型发布会,并且说会有 200 多家媒体和分析师到场时;我们还估计应该就是 AMD 吹吹牛,发表一下重申要回到高端市场的宣言之类的事情。但实际上 AMD 给出了部分架构上的详尽介绍,甚至还介绍了基本缓存结构,这出乎了我们的意料,估计这个星期媒体上都会是 AMD 的新闻了吧 ( 如果还真的有很多人关心图形卡之外的 AMD 的话 )。




2016-08-21 16:12 30楼
农企日常360度翻身 :wink: